From cTuning.org
Navigation: cTuning.org > CTools > MilepostGCC
It may not always be visible to the IT users, but developing and optimizing current and emerging computing systems using available technology is too time consuming and costly. Tuning hardwired compiler optimizations for rapidly evolving hardware makes porting an optimizing compiler for each new platform extremely challenging. Our radical approach is to develop a modular, extensible, self-tuning intelligent compiler that automatically learns the best optimization heuristics based on combining feedback-directed iterative compilation and machine learning. MILEPOST GCC is a machine learning based compiler that automatically adjusts its optimization heuristics to improve execution time, code size, compilation time and other parameters of any given program on any given architecture.
In 2006, after many years of discussions, the MILEPOST consortium has been created (INRIA, IBM Haifa, University of Edinburgh (project coordinator - Prof. Michael O'Boyle, R&D coordinator - Dr. Grigori Fursin), ARC International Ltd. and CAPS Entreprise) funded by EU FP6 program to start developing such a practical compiler based on previous research and experience of each partner. The development of the MILEPOST GCC and MILEPOST Framework has been coordinated by Dr. Grigori Fursin. The main idea was to move previously research technology on iterative feedback-directed compilation and machine learning techniques to production compilers to be able to use it on a range of architectures from embedded reconfigurable processors to high-performance computing systems. In contrast with other tools and projects that are either commercial, non open-source, exist only in publications or as unstable prototypes, MILEPOST GCC is the first open-source attempt to apply machine learning, statistical collective optimization and run-time adaptation inside a stable, production-quality compiler in order to simplify and automate the development of compilers, architectures, run-time systems and programs, and enable future self-optimizing smart computing systems.
MILEPOST GCC combines the strength of the production quality GCC that supports more than 30 families of architectures and can compile real, large applications including Linux, and the flexibility of the Interactive Compilation Interface that transforms GCC into a research compiler. It is currently based on predictive modeling using program and machine-specific features, execution time, hardware counters and off-line training. MILEPOST GCC includes static program feature extractor developed by IBM Haifa. MILEPOST/cTuning technology is orthogonal to GCC and can be used in any future adaptive self-tuning compiler using common Interactive Compilation Interface. For example, we hope to see MILEPOST-like technology in LLVM and ROSE compilers in the future. MILEPOST and cTuning infrastructure automates code and architecture optimization to improve execution time, code size, compilation time and other characteristics at the same time.
MILEPOST GCC is a wrapper around GCC with ICI that detects new -Oml flag, extracts program features, queries optimization prediction web-service connected to optimization repository and substitutes default optimizations with the suggested ones based on program similarities and machine learning to improve execution time, code size and compilation time on the fly.
In June, 2009, Grigori released MILEPOST GCC and integrated it with the cTuning tools: Collective Optimization Database, cTuning optimization prediction web-services, Interactive Compilation Interface for GCC, Continuous Collective Compilation Framework to enable collaborative community-driven developments after the end of the MILEPOST project (August 2009). You are warmly welcome to join cTuning community and follow/participate in developments and discussions using cTuning Wiki-based portal and 2 mailing lists: high volume development list and low volume announcement list.
We don't claim that MILEPOST GCC, MILEPOST Framework and cTuning tools can solve all optimization problems ;) but we believe that having an open research-friendly extensible compiler with machine learning and adaptive plugins based on production quality GCC that supports multiple languages and architectures opens up many research opportunities for the community and is the first practical step towards our long-term objective to enable adaptive self-tuning computing systems. With the help of the community, we hope to provide better validation of code correctness when applying complex combinations of optimizations, provide plugins for XML representation of the compilation flow, tuning of fine-grain optimizations/polyhderal GRAPHITE transformations/link-time optimizations, code instrumentation and run-time adaptation capabilities for statically compiled programs (see Google Summer of Code'09 program). We would also like to add support to MILEPOST GCC/cTuning tools to be able to optimize whole Linux (Gentoo-like) or optimize programs for mobile systems on the fly (for example, using Android, Moblin, etc) and extend this technology to enable realistic adaptive parallelization, data partitioning and scheduling for heterogeneous multi-core systems using statistical and machine learning techniques.
Currently, we use several iterative search strategies within CCC framework to find combinations of good optimization flags to substitute GCC default optimization levels for a particular architecture (such as -O0,-O1,-O2,-O3,-Os which we will not need in the future adaptive compilers) or tune optimization passes on a function-level for a particular program. Our preliminary experimental results (some are now available in the Collective Optimization Database) show that it is possible to considerably reduce execution time and code size of various benchmarks (MiBench, MediaBench, EEMBC, SPEC) on a range of platforms (x86, x8664, IA64, ARC, Loongson/Godson, etc) entirely automatically.
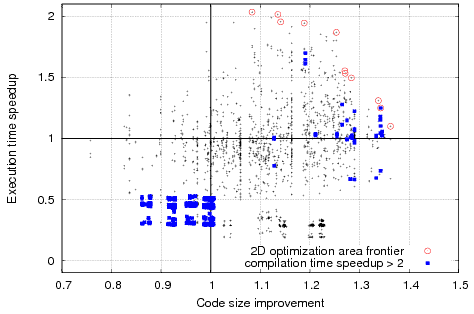
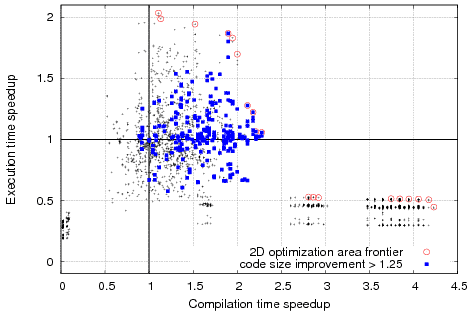
Typical non-trivial distribution of optimization points (including optimal frontier cases) in the 2D space of execution time speedups vs code size improvements and vs compilation time speedups of a susan_corners program on AMD Athlon64 architecture with GCC 4.4.0 during automatic program optimization using ccc-run-glob-flags-rnd-uniform plugin from CCC framework with uniform random combinations of more than 100 global compiler flags (each flag has 50% probability to be selected for a given combination of optimizations). Similar data for other benchmark, datasets and architectures is available in the Collective Optimization Database. cTuning technology should help users to find or predict good optimization points in such complex spaces using "one-button" approach.
MILEPOST GCC can be used interactively in research on adaptive computing through the Interactive Compilation Interface (we currently support optimization pass selection and reordering, plugins and event mechanism to invoke any passes on demand (such as program feature extraction pass) or tune cost-models of specific transformations within passes). CCC framework provides a milepost-gcc wrapper that detects -ml flag, extracts program features, queries optimization prediction web-service connected to optimization repository and substitutes default optimizations with the suggested ones based on program similarities and machine learning to improve execution time or code size on the fly.
We hope that this technology will considerably minimize repetitive time consuming tasks and human intervention when optimizing computing systems and will reduce time to market for new products thus boosting innovation and novel research.
Note: cTuning is an ongoing evolving project - please be patient and tolerant to the community and help us with this collaborative effort!
Acknowledgments
Here is a list of colleagues who contributed to ICI or provided feedback/ideas (in alphabetical order):
- Fabio Arnone (STMicroelectronics, France)
- Phil Barnard (ARC, UK)
- Francois Bodin (CAPS Entreprise, France)
- Zbigniew Chamski (InfraSoft IT Solutions, Poland)
- Bjorn Franke (University of Edinburgh, UK)
- Grigori Fursin (UVSQ/INRIA, France) (MILEPOST R&D coordinator and main developer)
- Taras Glek (Mozilla, USA)
- Yuriy Kashnikov (UVSQ, France)
- Hugh Leather (University of Edinburgh, UK)
- Abdul Wahid Memon (UVSQ, France)
- Cupertino Miranda (INRIA, France)
- Mircea Namolaru (IBM, Israel)
- Diego Novillo (Google, USA)
- Sebastian Pop (AMD, USA)
- Joern Rennecke (ARC, UK)
- Jeremy Singer (University of Manchester, UK)
- Basile Starynkevitch (CEA, France)
- Ayal Zaks (IBM, Israel)
- Other colleagues from MILEPOST project, HiPEAC network of excellence, IBM, NXP, STMicroelectronics, ARC, CAPS Enterprise, Mozilla, UVSQ ...